
Working with a dubbing script can be very tricky, especially when dealing with time-sensitive Japanese scripts.
This is partially because the language consists of 3 writing systems: hiragana (e.g., “いろは”), katakana (e.g., “イロハ”), and kanji (e.g., “百花繚乱”). While each hiragana/katakana character represents a syllabary of this phonetic lettering system, kanji may contain one or more hiragana syllable(s).
For instance, “承” can either be read with 2 syllables as “しょう”, or “うけたまわ”, depending on the context. Notice the former takes only 2 syllables, while the latter requires 5 syllables! This is the reason why duration estimate with simple character count never works in the Japanese voice script. Could it be why we often encounter over 8 seconds worth of lengthy text for a mere 2-second voice spot? God only knows…
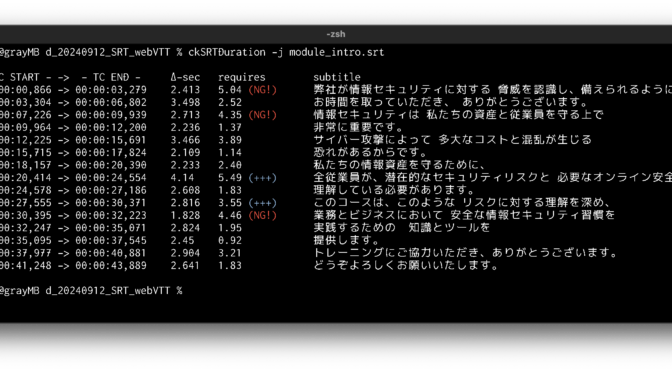
I took a closer look at this problem, and came up with a sensible solution: 1) expand all kanji characters to hiragana syllables, 2) then count the numbers of all hiragana/katakana characters, and 3) apply algorithm to calculate duration. Here it is… introducing “ckSRTDuration ver. 1.22″, a custom-built CLI tool to analyze the script’s durational integrity:
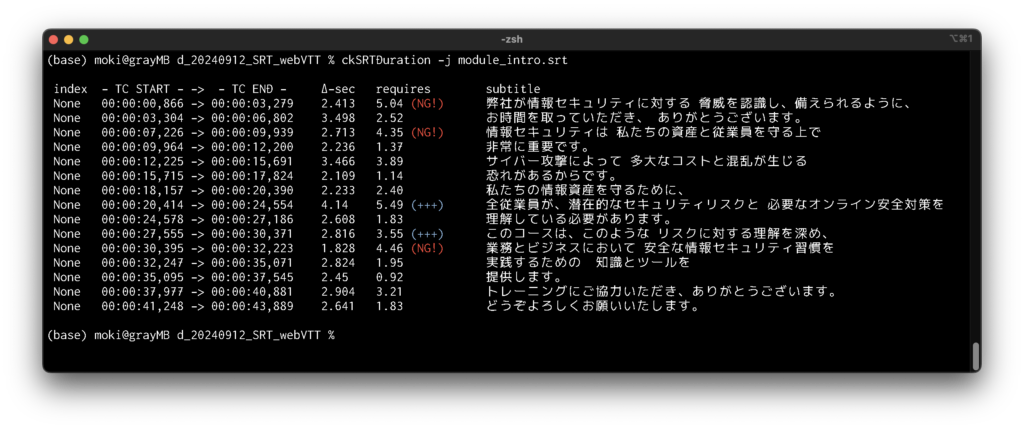
In this example above, this SRT-based script – initially intended for on-screen use – comes with timecode info, indicating how many seconds is allowed on each line. Where translation is too verbose, “(NG!)” is indicated in red (of course we can yap ridiculously fast like a chipmunk, just to read all characters… but then presentation itself won’t make sense in the end!)
We utilize this tool for pretty much all dubbing jobs, free of charge. It saves a lot of time for me and my clients after all.